

The High Cost of Keyword Search
Semantic search, based on deep neural networks, is changing information retrieval.

When most computer scientists think of information retrieval, statistical keyword algorithms like TF-IDF and BM25 probably come to mind. These are deployed in open source systems such as Apache Lucene and Apache Solr. Cloud versions of keyword search are available from companies like Elasticsearch and Algolia.
What you may not know is that advancements in natural language processing (NLP), particularly the introduction of transformers in 2017, have ushered in a new flavor of information retrieval known variously as neural information retrieval (neural IR for short) and semantic search. The defining characteristic of these systems is that they apply neural networks to understand language at a deeper level than keyword search. This enables them to surface a broader variety of relevant content, while showing results with greater precision.
Neural IR systems are in their infancy, and I would recommend An Introduction to Neural Information Retrieval by Mitra and Craswell if you’re interested in gaining a deeper appreciation of the field. Amazon Kendra, released early in 2020, is the first commercial example of such a system, while Microsoft Semantic Search, released in April 2021, and ZIR Semantic Search are more recent.
Goals
In the rest of this article, we’ll build a search over a small collection of hotel reviews. I’ll use ZIR’s semantic search platform because it’s designed for easy and affordable integration into SaaS and PaaS products, and has the unique ability to index and search content across several languages. You can download the source code for this tutorial from GitHub at amin3141/zir-souffle.
A Collection of Hotel Reviews
The OpinRank Dataset includes an extensive collection of hotel reviews from major cities around the world. For the purposes of the demo, we’re going to build a search over the three most-reviewed hotels in San Francisco: Best Western Tuscan Inn, Sheraton Fisherman’s Wharf Hotel, and The Westin St. Francis.
The datafile has a simple tab-delimited format. The first column is the date of the review, the second column is the title, and the third column is the actual text:
Nov 16 2009 The Prefect Hotel Have visited San Francisco several times and this…
Nov 15 2009 Great location and great hotel My friend and I…
Nov 13 2009 Perfect experience This hotel was perfect. It was a brilliant location…
To begin with, we’ll separate every review into its own JSON document and save it as a separate file. We’ll include the name of the hotel and the date of the review as metadata (ZIR Semantic Search returns metadata automatically with search results.)
{
“documentId”: 1036995557631769528072025822232699890,
“metadataJson”: “{\”date\”: \”Apr 23 2005\”, \”hotel\”: \”best_western_tuscan_inn_fisherman_s_wharf_a_kimpton_hotel\”}”,
“section”: [
{
“text”: “We spent six nights at the Tuscan Inn and have nothing but rave reviews for this hotel! The location was perfect. Walking distance to Cable Cars,Wharf, Bus 47 and F Line. Great restaurant with a friendly staff. Everyone was pleasant and very helpful. Nice clean rooms and a spaciousbathroom. We are anxious to return!Mary and Jack from Scituate MA”
}
],
“title”: “Great Hotel”
}
The document ID is the murmur3 x64 128-bit hash of the full review. When search results are returned, this ID is included, which allows the querying system to easily retrieve the full document. To facilitate lookup, the opinrank2json.py program, which implements this logic, also creates a SQLite database containing all the reviews in the files, keyed by document ID.
Indexing the Data
Just as with keyword search systems like Algolia and Elasticsearch, you must push the content you want to search into the platform so that it can be indexed. ZIR Semantic Search provides gRPC-based APIs for doing this, in addition to UI-based drag-and-drop to support rapid prototyping.
- Login to your account.
- Use the left hand menu to navigate to corpora, and create a new corpus named “Hotel Reviews”. A corpus is just a named collection of documents and textual material that can be queried later.
- Click and open the Hotel Reviews corpus. Drag and drop the folder containing the review JSON documents into the corpus.
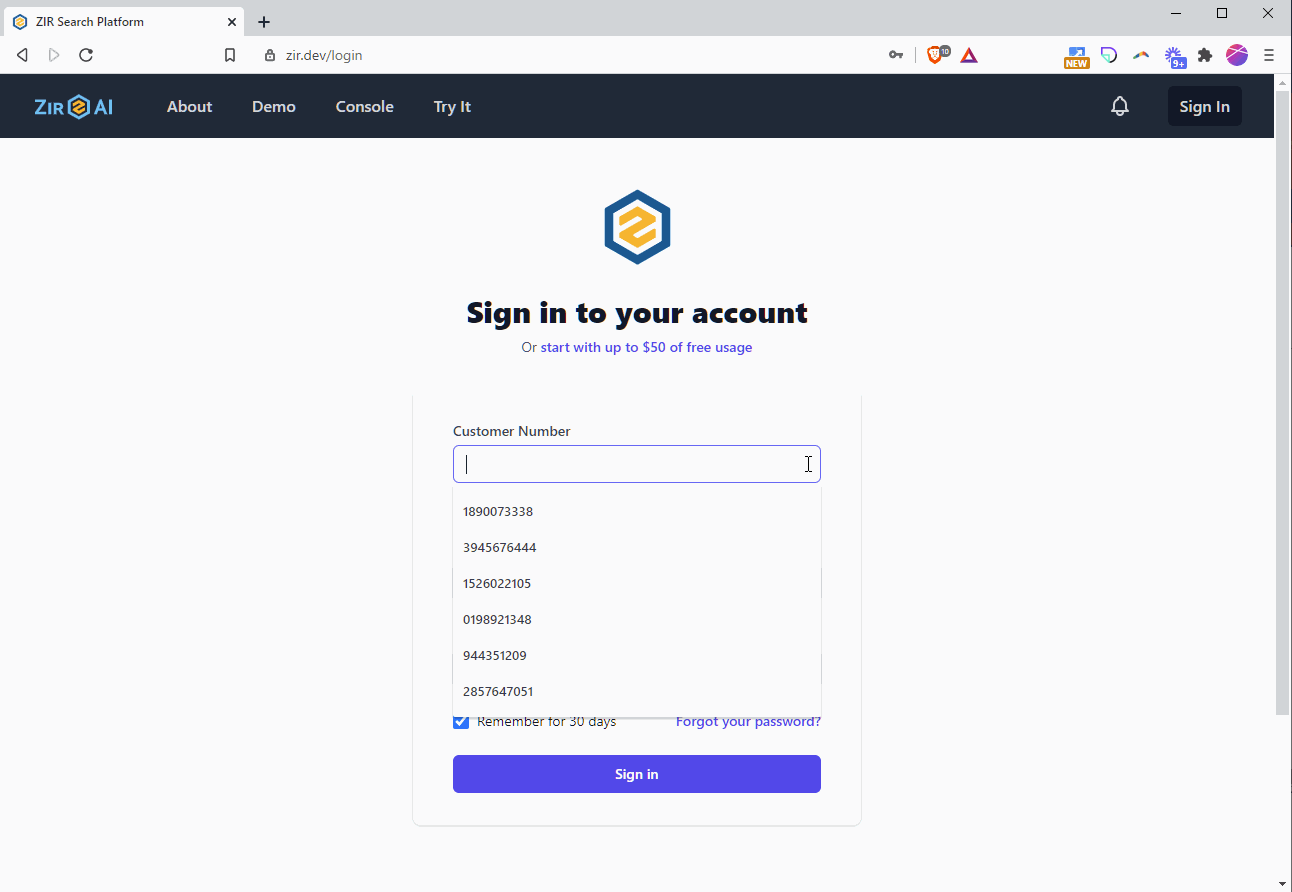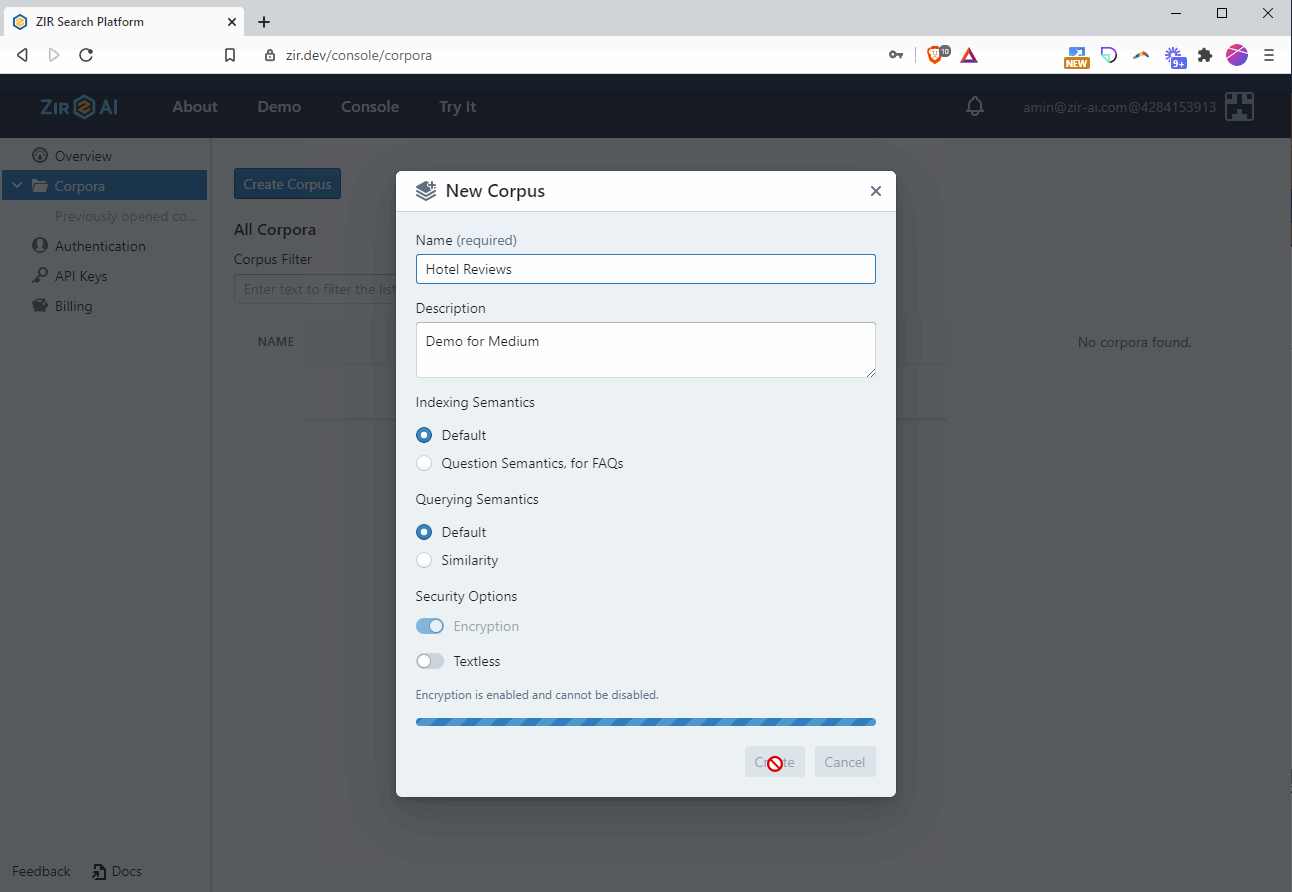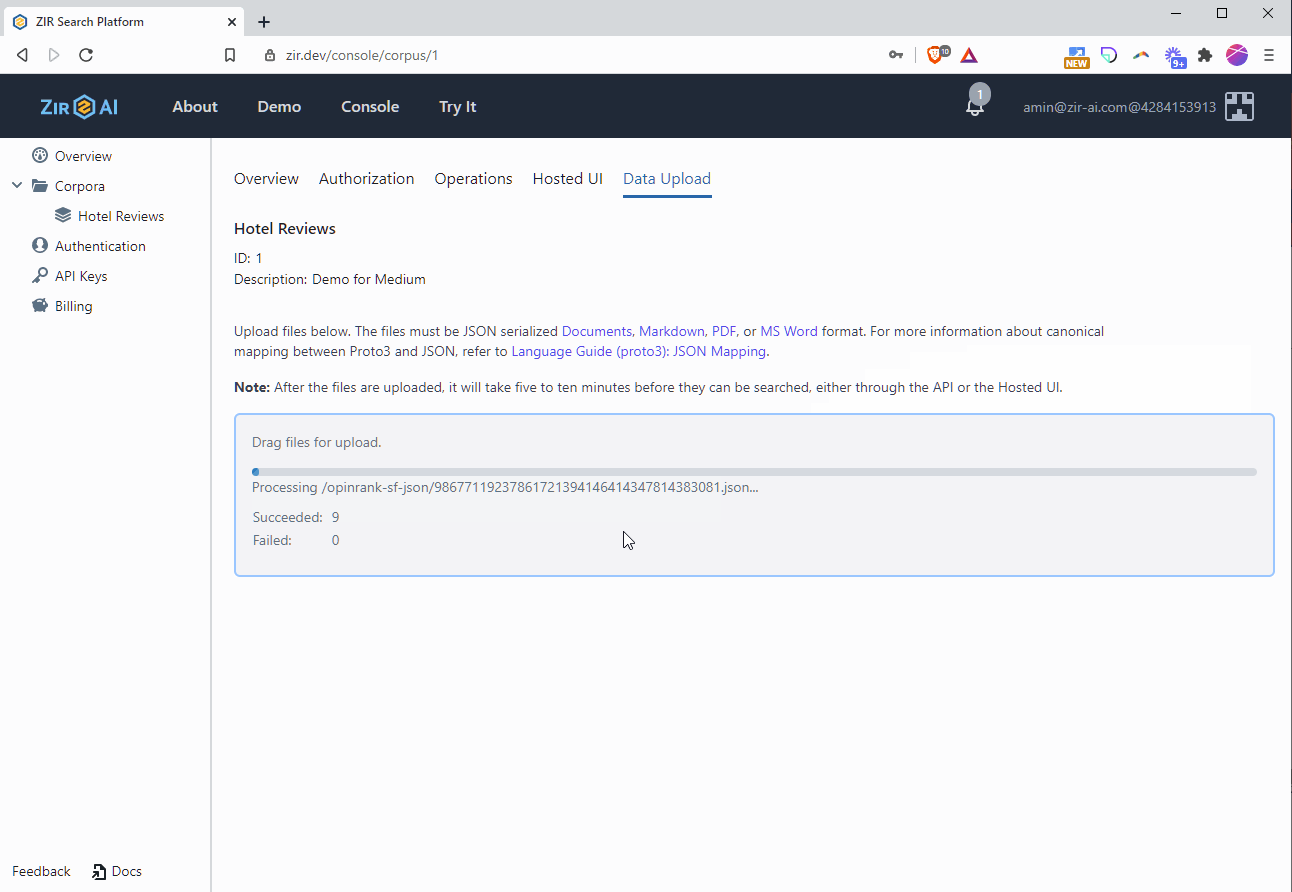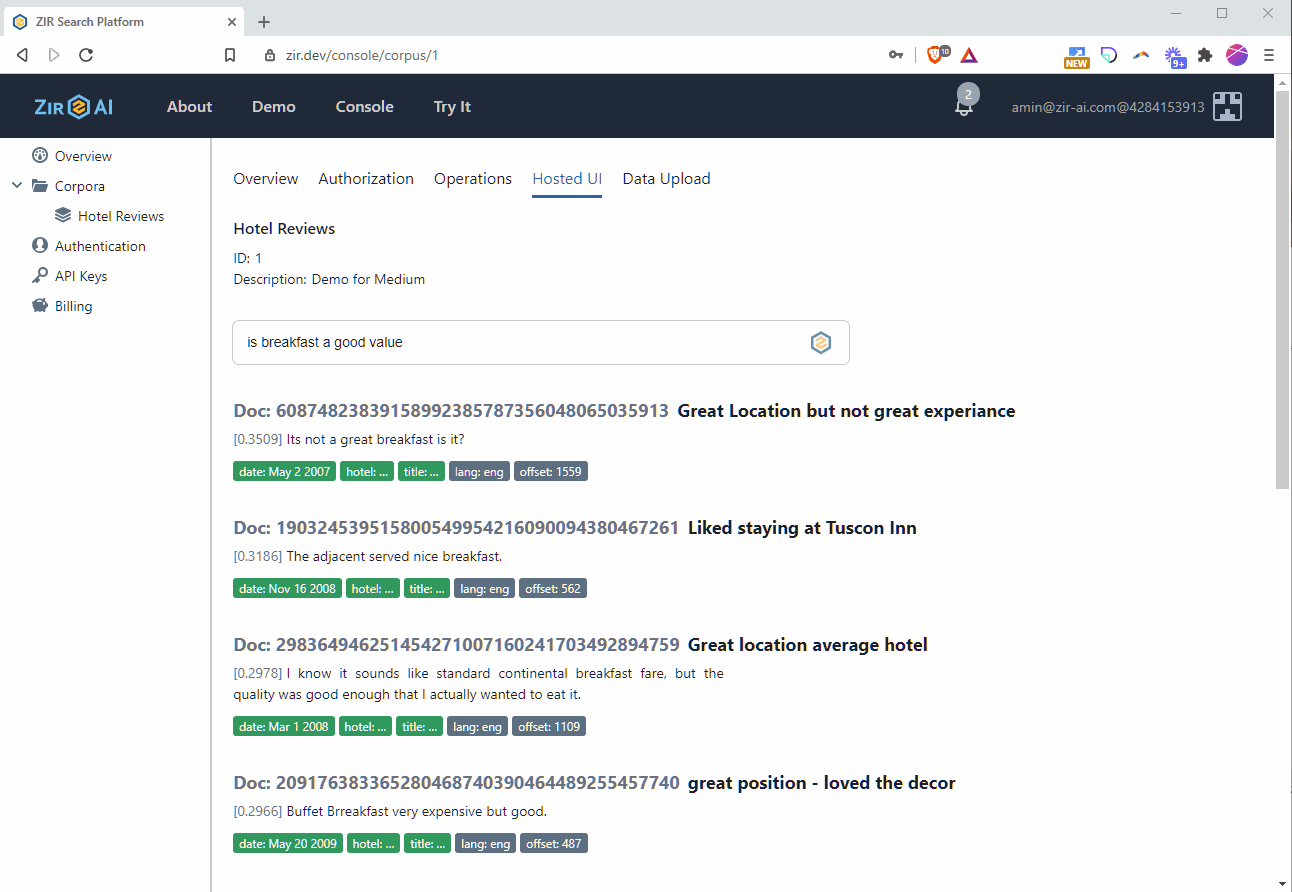
Within five to ten minutes of being added, the documents will become searchable. You can verify this by running a query on the Hosted UI tab and checking that results are being returned.
Security
Since all access to the platform is authenticated, we’ll need a valid user to connect and run queries. For now, we’ll use the OAuth 2.0 Client Credentials Flow for convenience. Normally, you should only use this flow when the client is running in a trusted environment and the credentials can be kept secure, such as within a running server.
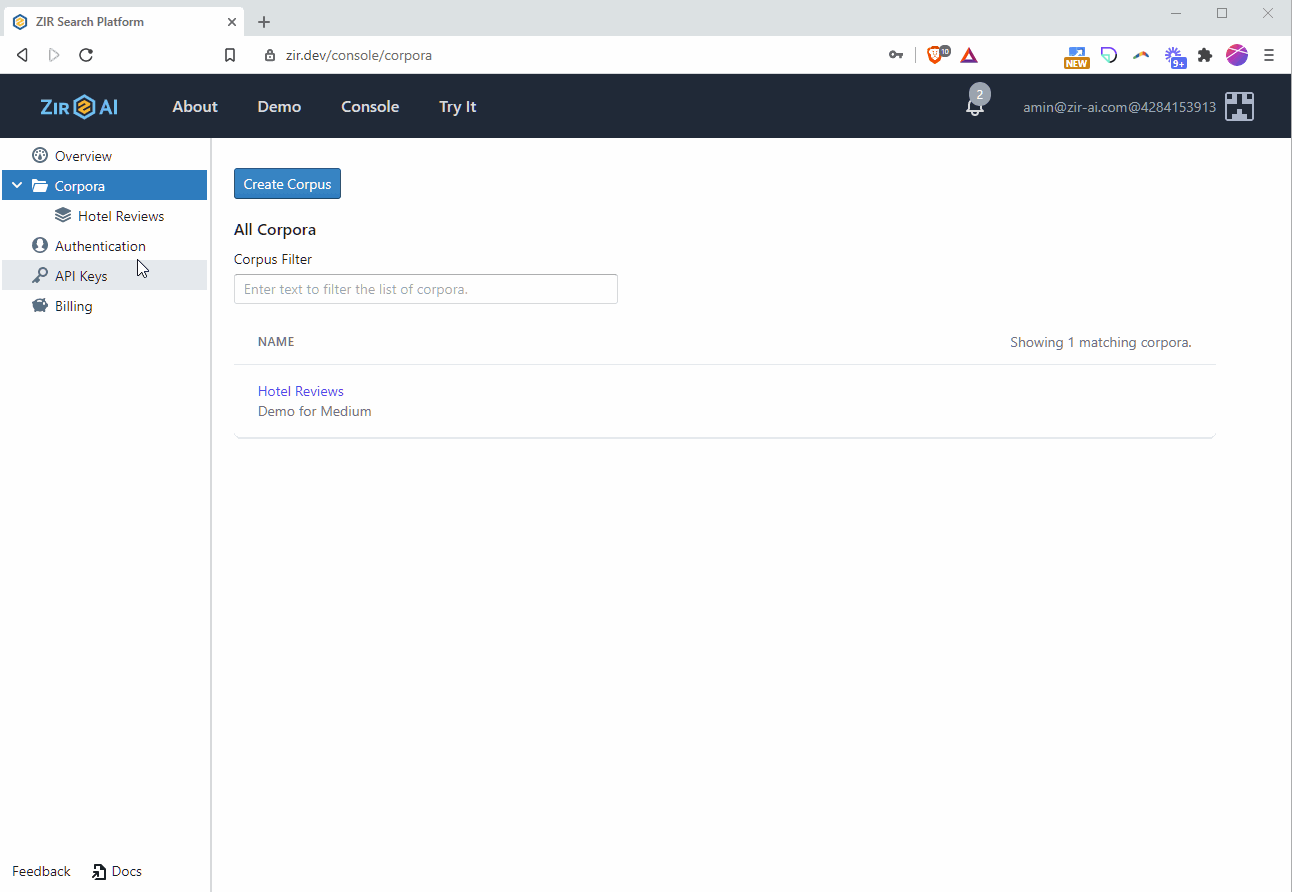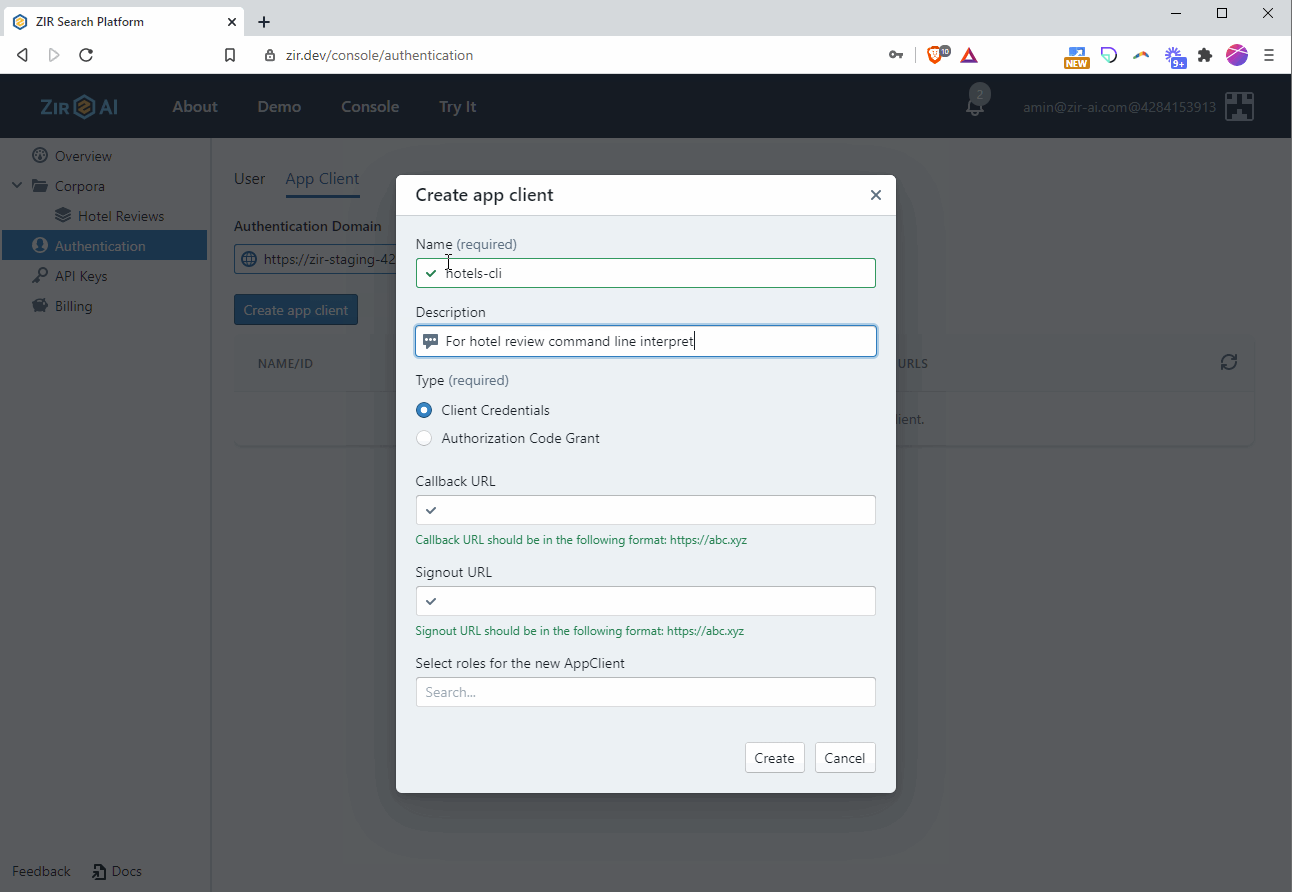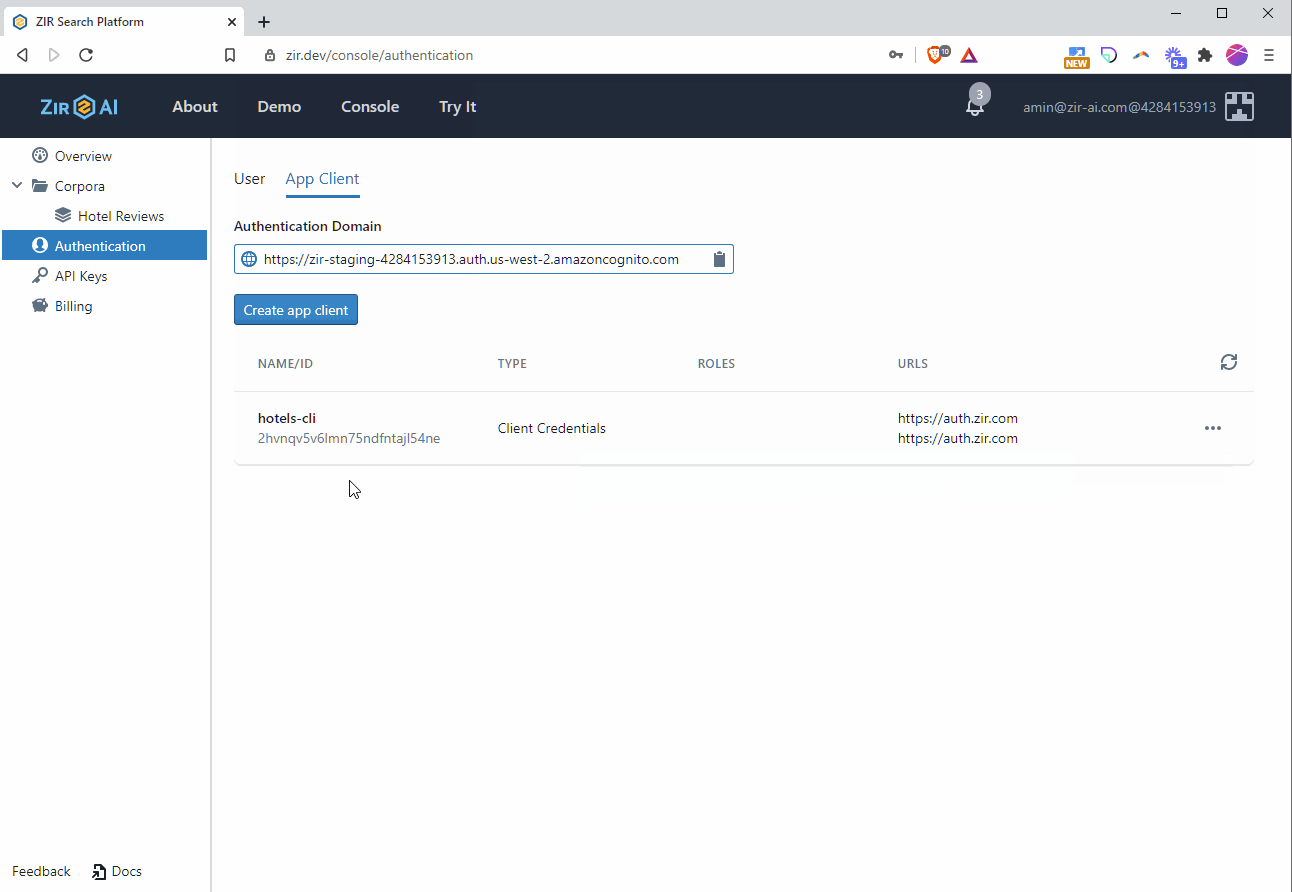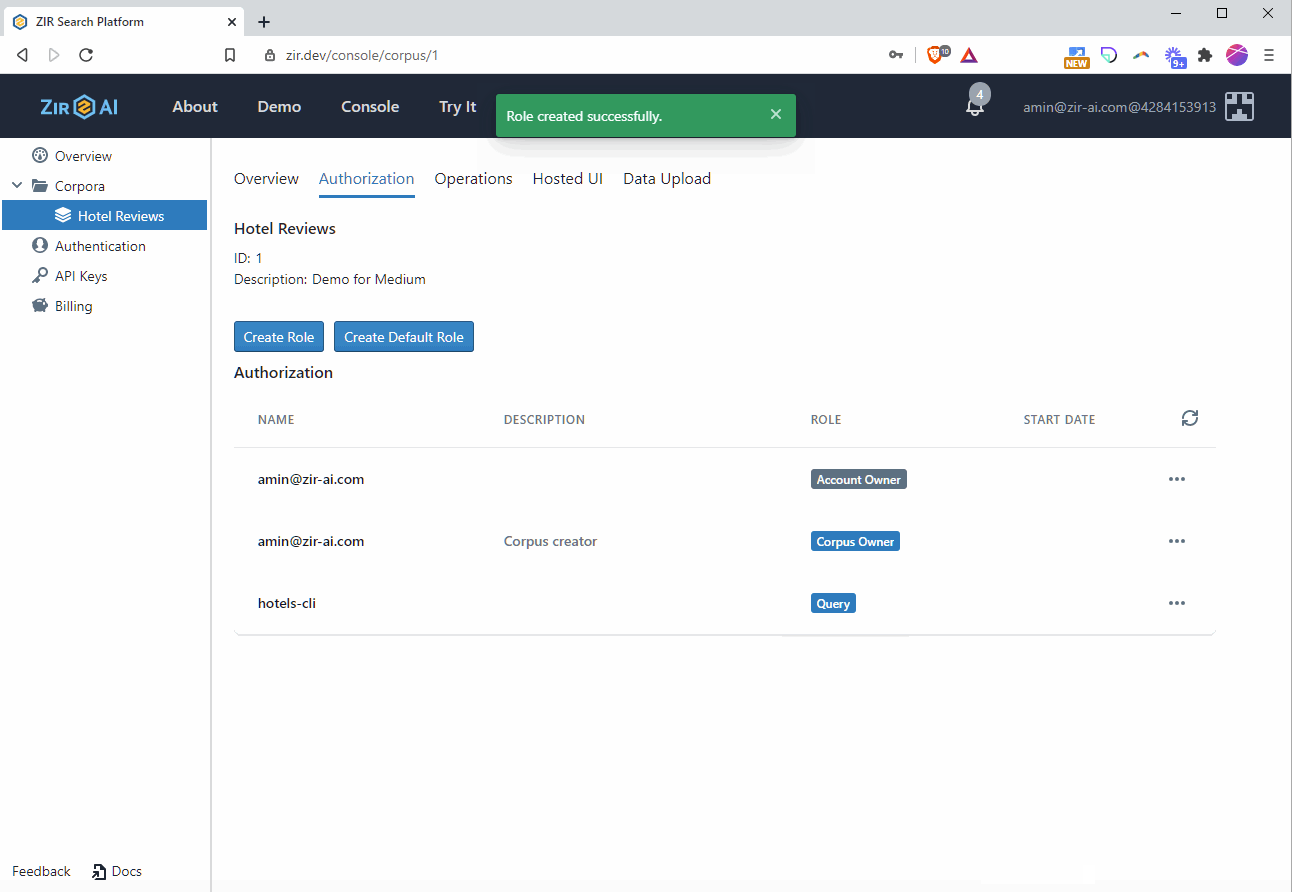
- Using the left hand menu, navigate to Authentication → App Client, and click on the “Create app client” button.
- Give it a name (e.g. hotels-cli), set the type to Client Credentials, and enter any URL for callback and signout (e.g. https://auth.zir.dev). Note the client id and client secret, as you’ll need them both when connecting and running queries.
- Click back to the corpus, click the Authorization tab, and click the “Create Role” button. Choose the app client you created in step two and grant query privileges on the corpus to it.
A Semantic Search CLI
Neural approaches to information retrieval revolve around vectorization of words, sentences, and paragraphs. The neural network is the mathematical function that takes a phrase as input and produces a high dimensional vector as output. These vectors represent the semantics of the phrase in such a way that phrases with related semantics share geometric structure in the vector space. These vectors are frequently referred to as embeddings.
Due to this abstractive quality, neural systems are robust to misspellings and other typos which throw off keyword systems. In contrast, keyword systems must generally configure stop word removal, word stemming, and spell correction in order to get good results.
To keep the tutorial simple, we’ll build a Python based command-line interpreter that accepts queries and returns top matching results from the customer reviews we added earlier. ZIR Semantic Search returns the following information in every result:
- The document ID and metadata. The client uses this information to join the result to the original information source, and display it in context. We’ll use the document ID to lookup the full review and display it.
- The relevant snippet. A document generally covers many topics, so the search result includes the part it identifies as the most relevant. As a general rule, it’s helpful to display a little bit of the surrounding text when displaying this snippet to your users.
- A score. The score is a real number that correlates with confidence in the search result. Importantly, the score is not a calibrated probability, so it should be interpreted with caution. However, it can safely be used as-is for downstream machine learned models such as rerankers.
I’ve implemented a complete client in hotels.py. The code below shows how the query is submitted using the requests library.
Exploring Semantic Search
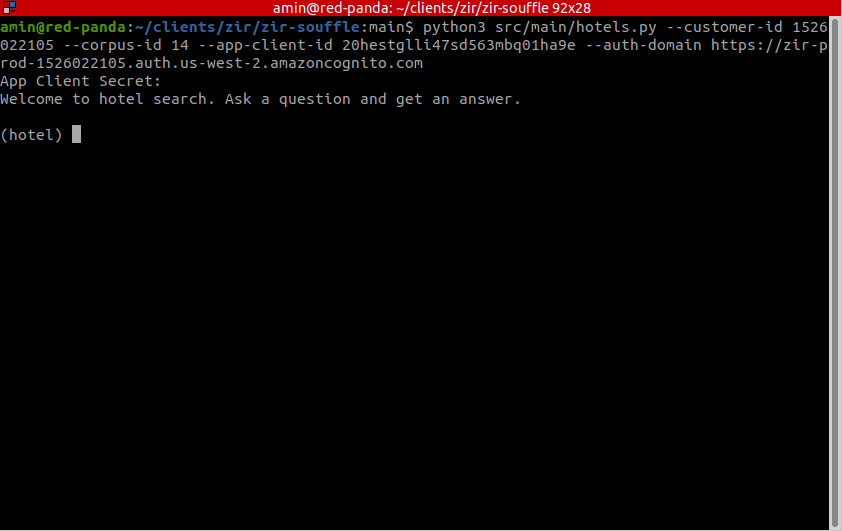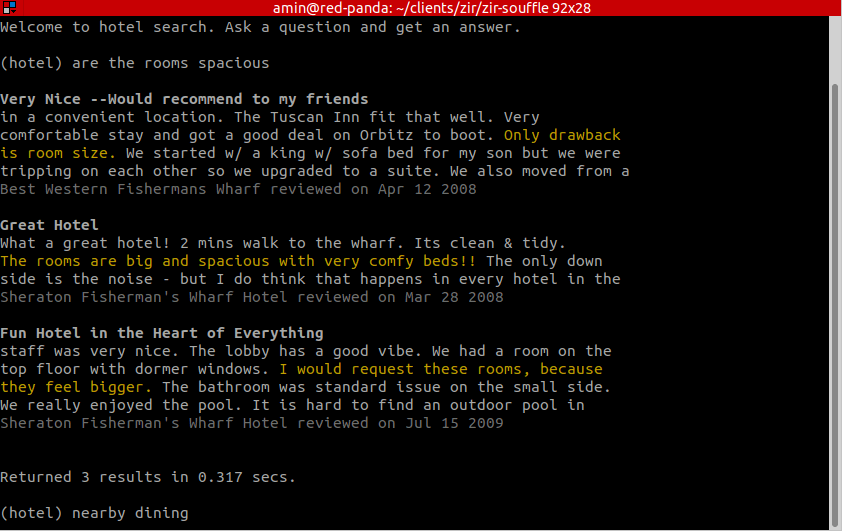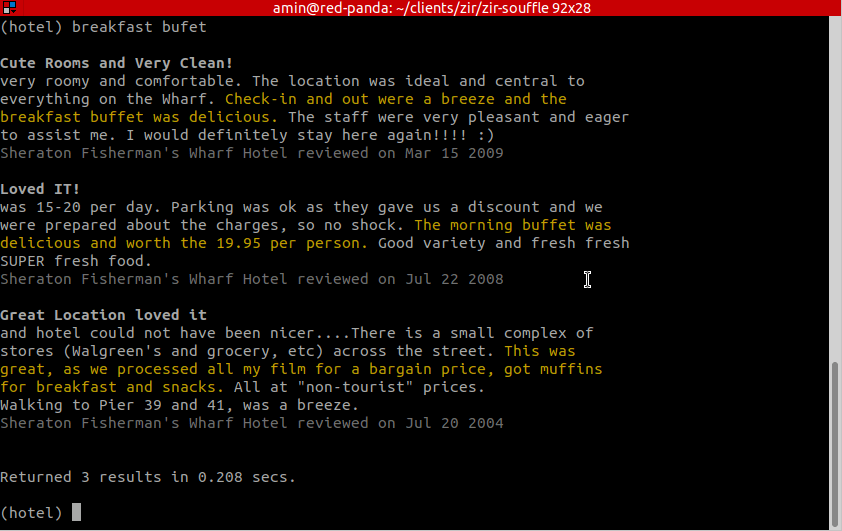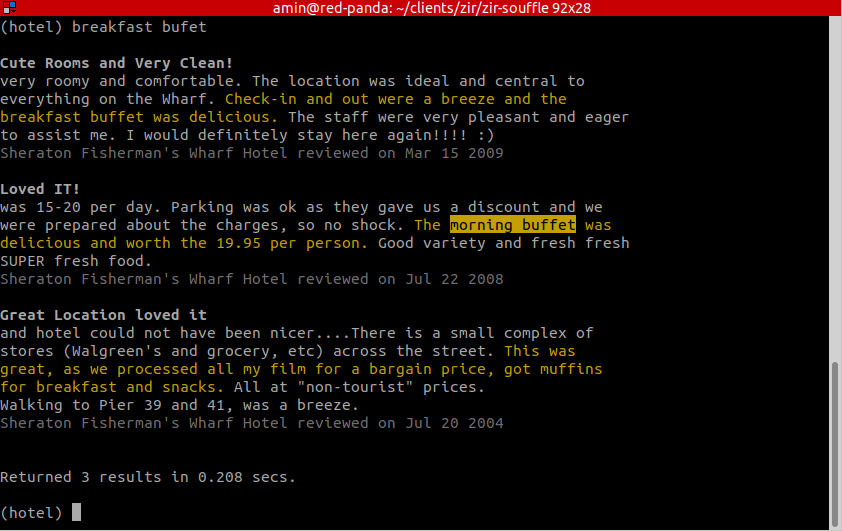
The animated gif below shows an interactive semantic search session. The results for the first question, “are the rooms spacious”, demonstrate that the search understands the semantics of the word spacious, and can therefore return results like “Only drawback is room size”.
The second query asks about “nearby dining”, and the search is able to return relevant results without keyword overlap, like “Alos [sic], the food in the adjoining restaurant was very good!”
Finally, the third query intentionally misspells a key term, “breakfast bufet”, and the search nevertheless returns results for breakfast buffet and even morning buffet!
Conclusion
A great deal of research has established the importance of relevance in engaging and satisfying users. For example, a 2012 study by Microsoft demonstrated a causal link between degraded relevance and long-term reductions in user engagement with Bing Search. And Google famously outmaneuvered Alta Vista, Lycos, and others by moving beyond keywords to incorporate information about the linking structure of web pages when ranking search results.
Whether your objective is to improve user engagement, or you simply want to help your users quickly find the most relevant information, you pay the high cost of keyword search every day in the form of missing and irrelevant search results. Applications as diverse as e-commerce, customer support, enterprise search, and legal e-discovery all stand to benefit from the emergence of semantic search technology, which is poised to resculpt the landscape of information retrieval.
Acknowledgements
- Cover image photo by Emily Levine on Unsplash
- Anne Bonner for reviewing.

