

Semantic search helps chatbots answer more questions
Semantic search makes it easy for chatbots to utilize unstructured text, like customer reviews, to answer more questions.

Not too long ago, chatbots and assistants didn't work well. The ones that did, like Amazon Alexa, were developed by companies with enormous R&D budgets and specialized ML and NLP teams.
But due to leaps in the performance of NLP systems made after the introduction of transformers in 2017, combined with the open source nature of many of these models, the landscape is quickly changing. Companies like Rasa have made it easy for organizations to build sophisticated agents that not only work better than their earlier counterparts, but cost a fraction of the time and money to develop, and don't require experts to design.
Yet, for all the recent advances, there is still significant room for improvement. In this article, we'll show how a customer assistant chatbot can be extended to handle a much broader range of inquiries by attaching it to a semantic search backend.
A Basic Chatbot for Atlantis Dubai
When Hotel Atlantis in Dubai opened in 2008, it quickly garnered worldwide attention for its underwater suites. Today their website features a list of over one hundred frequently asked questions for potential visitors. For our purposes, we'll use Rasa to build a chatbot that handles inquiries on these topics.
You might be wondering what advantage the Rasa chatbot provides, versus simply visiting the FAQ page of the website? The first major advantage is that it gives a direct answer in response to a query, rather than requiring customers to scan a large list of questions.
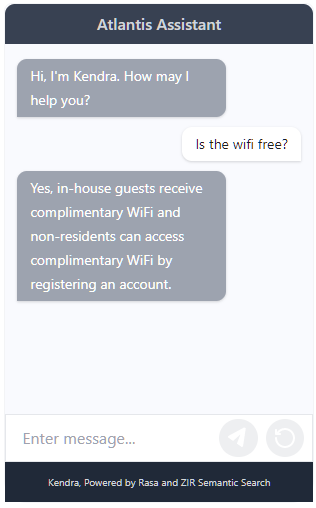
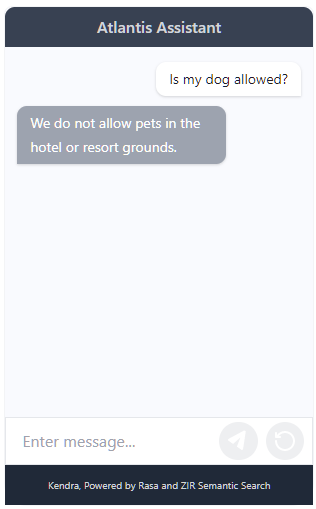
Secondly, compared to a Ctrl-F search, Rasa finds content more intelligently. By virtue of being powered by NLP models, it can handle misspellings and paraphrases gracefully. For example, if I ask "Is my dog allowed", Rasa gives me the result below, whereas a Ctrl-F search for "dog" would return nothing because the FAQ question is Do you allow pets in Atlantis Dubai?
The source code for our bot is available at https://github.com/amin3141/zir-rasabot and the final version is deployed on our demo page. The files below provide the core knowledge base implementation using Rasa's authoring syntax.
- nlu.yml, Contains FAQs together with their variants.
- domain.yml, Contains responses and declaration of the intents.
- rules.yml, Maps intents defined in nlu.yml to responses defined in domain.yml.
Customer reviews: An untapped source of information
With the rise of the internet and online e-commerce, customer reviews are a pervasive element of the online landscape. Reviews contain a wide variety of information, but because they are written in free form text and expressed in the customer's own words, it hasn't been easy to access the knowledge locked inside.
Hotel Atlantis has thousands of reviews and 326 of them are included in the OpinRank Review Dataset. Elsewhere we showed how semantic search platforms, like ZIR Semantic Search, allow organizations to leverage information stored as unstructured text—unlocking the value in these datasets on a large scale.
Rasa includes a handy feature called a fallback handler, which we'll use to extend our bot with semantic search. When the bot isn't confident enough to directly handle a request, it gives the request to the fallback handler to process. In this case, we'll run the user's query against the customer review corpus, and display up to two matches if the results score strongly enough. The source code for the fallback handler is available in main/actions/actions.py. Lines 41-79 show how to prepare the semantic search request, submit it, and handle the results.
How can we decide that the bot isn't confident enough? For the purposes of this article, we cheated: We computed our metric of choice, F1 score, directly on our evaluation data, and chose a threshold that maximized it. While this does not prevent us from drawing conclusions from the evaluation results, we have to remember that the baseline chatbot was given an unrealistic advantage.
We also use a threshold of 0.3 to determine whether the semantic search fallback results are strong enough to display. Crucially, this threshold was obtained from an unrelated dataset. Therefore, we expect our metrics to accurately reflect real-world performance.
Comparing Bots
The performance of complex systems must be analyzed probabilistically, and NLP powered chatbots are no exception. Lack of rigor in evaluation will make it hard to be confident that you're making forward progress as you extend your system. The rest of this section describes our methodology for evaluating the chatbot.
First, we constructed an evaluation set of 63 questions. We asked five individuals, who had stayed at hotels before, what questions they might be interested in knowing about Hotel Atlantis in Dubai, prior to booking a room. There are a few key points to note in the prompt: First, it introduces the location of the hotel, Dubai, to allow for geographically relevant questions such as How far is it from the beach? Second, it also sets a goal that aligns with a realistic business motivation for building such a bot in the first place, that is, to help potential customers decide if it's a place they'd like to stay.
To characterize the performance of the bot, we begin with the standard four-category classification of answers that will be familiar to anyone who's worked with ML systems before:
- True positive: The chatbot answered the question correctly. In our evaluation, a single evaluator made the call, although if your budget allows, it's more reliable to use multiple evaluators.
- False positive: The chatbot answered the question incorrectly.
- False negative: The chatbot withheld from answering a legitimate question. This is indicated when the system replies with I'm sorry, I don't have any information about that.
- True negative: Describes the case where the chatbot refrains from answering an illegitimate question, for example, How deep is the Marinara Trench? However, true negatives don't exist in our dataset because all questions are on-topic.
Using these classes, we'll compute precision, which is the proportion of answered questions that are correctly answered, and the true positive rate, also known as recall, which is the percentage of valid questions that can be correctly answered. The following formulas express this:
$$ \textup{P} = \frac{\textup{TP}}{\textup{TP} + \textup{FP}} $$
$$ \textup{TPR} = \frac{\textup{TP}}{\textup{TP} + \textup{FN}} $$
To characterize the performance of the system as a single number, we'll turn to the F-score. The factor β in the equation below specifies that the true positive rate is considered β times more important than precision. β should be chosen to accurately reflect the relative costs associated with false positive and false negative results.
$$ F_{\beta} = (1 + \beta^{2}) \frac{\textup{P} \cdot \textup{TPR}}{\beta^2 \cdot \textup{P} + \textup{TPR}} $$
Unfortunately, this is difficult to estimate because the relative costs vary from question to question, and also depend on how wrong the answer is. For this reason, we will weigh them equally, that is, β is 1.
Summary and Analysis
The answers from the default chatbot and the chatbot with fallback enabled were evaluated and categorized as follows:
- Default: (TP=7, FP=7, TN=0, FN=49)
- Fallback: (TP=29, FP=24,TN=0, FN=10)
The chart below illustrates their relative performance on the metrics discussed above.
The biggest improvement is to the true positive rate of the chatbot. On the evaluation set of realistic questions, the chatbot went from correctly answering 13% of questions to 74%. This also increased the F1 score from 20% to 63%. Most significantly, this improvement was achieved easily by accessing existing reviews with semantic search.
What about precision? Surprisingly, it appears to have improved, too, from 50% to 55%. However, the 90% confidence interval makes it clear that this difference is well within the margin of error, and no conclusions can be drawn. A larger set of questions that produces more true and false positives is required. Had the interval not been present, it would have been much harder to draw this conclusion. A good rule of thumb is that statistics presented without confidence intervals be treated with great suspicion.
Have we reached the end of the road? Can we proclaim, as one erstwhile American President once did, "Mission accomplished!" In our case, as in his, the answer is, not so fast! In the final section of this article, we'll discuss a few additional things you should consider when adding semantic search to your chatbot.
Concluding challenges
Customer reviews may mention facts that misalign with official policy. For example, if a customer asks about checkout times, an informative review might state that checkout is 10am, but I left at 1pm and it wasn't a problem. Thus, the bot needs to make it clear when it's answering authoritatively, and when it's reaching for answers in secondary sources. One way is to preface the results with a statement like Here's what other customers had to say:
And what if a customer asks whether the rooms at Hotel Atlantis are clean? Would management want the bot to volunteer the carpets stink and there are cockroaches running on the walls! It's hard to imagine, even if the review were accurate. Periodically reviewing responses produced by the fallback handler is one way to ensure these situations don't arise. Another is to filter out negative reviews from the corpus.
Inter-annotator Agreement
When we evaluated our chatbot, we categorized every response as a true or false positive or negative. This task is called annotation, and in our case it was performed by a single software engineer on the team. Almost certainly, if you ask another person to annotate the responses, the results will be similar but not identical.
For this reason, it's good practice to include multiple annotators, and to track the level of agreement between them. Annotator disagreement also ought to reflect in the confidence intervals of our metrics, but that's a topic for another article.
Resources
- The Hotel Atlantis Chatbot with fallback enabled.
- Evaluation results for all 63 questions
- The high cost of keyword search includes a tutorial showing how to upload customer reviews into ZIR Semantic Search.
- Rasa for building conversational systems with the latest language understanding technology.
Amin Ahmad is cofounder of ZIR AI. The chatbot was developed by Basit Anwer.

